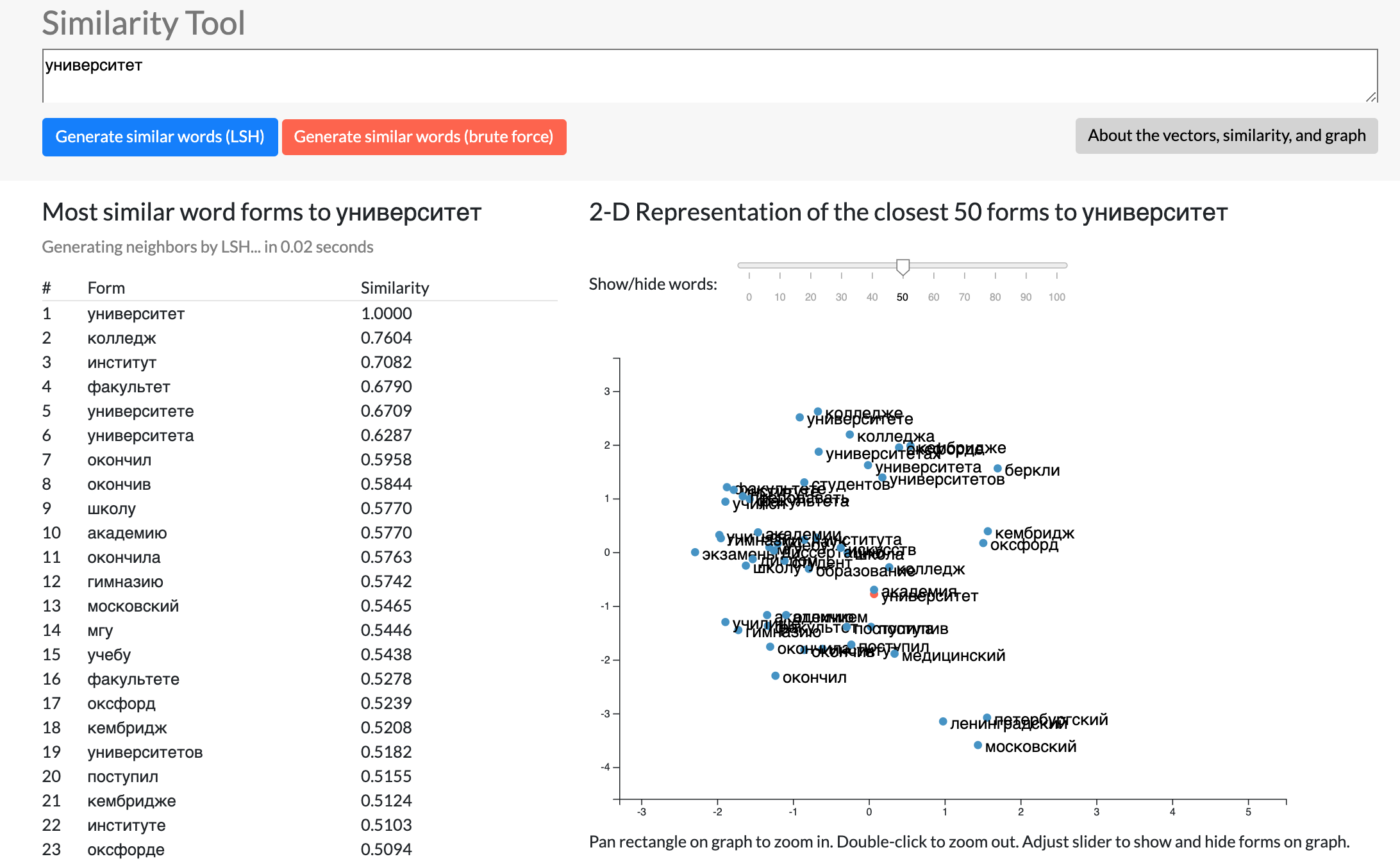
Similarity Tool
Users can input any word into the Similarity Tool in Visualizing Russian to generate lists and graphs of similar words. Similarity is determined by the word embedding vectors (embedding vectors are numerical vector representations of words, usually created by parsing huge amounts of text and analyzing words in their sentence context). The distance between vectors can be computed using different distance metrics, and I used cosine similarity here.
The tool gives two options for generating similar words. The first is LSH (Locality Sensitive Hashing), which is an algorithmic technique that hashes similar input items into the same "buckets" with high probability. It is a type of "near-neighbor" search, which finds approximate near neighbors of vectors, so it is not always 100% correct. However, it is fast! Most LSH queries for the Similarity Tool take less than one second.
The other option for generating similar words is the brute force method which simply loops over all of the words in the dictionary and compares the target word with each search word. Because there are thousands and thousands of words in the dictionary, this takes longer, usually more than ten seconds for the Similarity Tool. However, it is 100% accurate based on the data and will always return the same list of similar words, so this can be helpful for experimental purposes.
The Similarity Tool can be helpful for language learners who want to learn related words in the vocabulary. For example, a search on the word "football" will return other sports terms, like different games and sports (hockey, basketball, golf, chess), words pertinent to the game of football/soccer (match, box, stadium), and words associated with sports in general (sport, games, to play, championship). This tool is also potentially of interest to researchers looking at contextual word usage and synonyms in Russian.
You can try the live tool on the Visualizing Russian website.
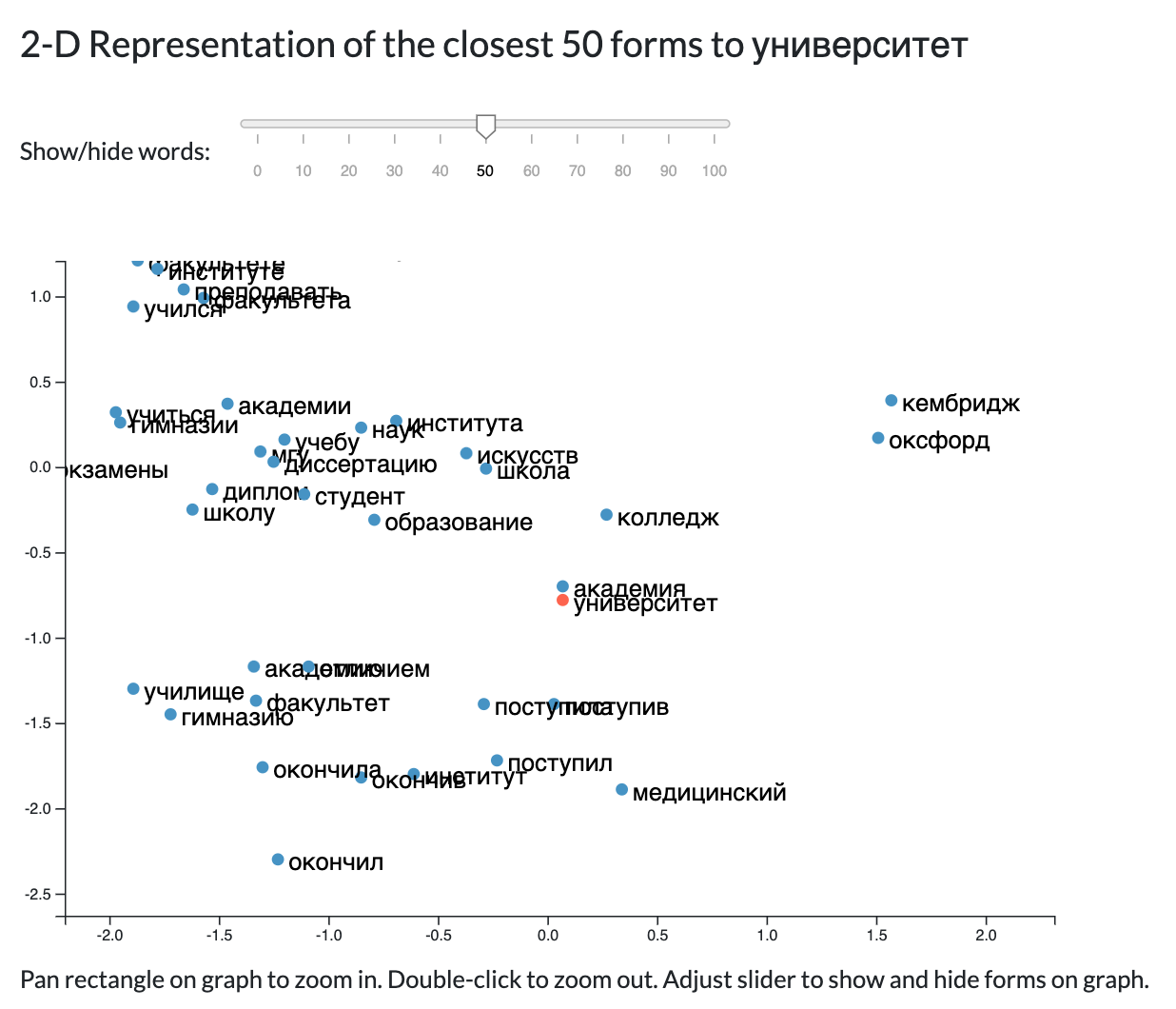
Demo of the Similarity Tool on the word "university" (universitet/университет). The ranked list of similar word (forms) is on the left. On the right a graph of similar word vectors. The 300-dimension vectors are squished down to 2-dimensions using principal component analysis.
Below: Panning a rectangular on the graph allows a user to zoom in on a certain section of the graph. In this area, we see several of the words similar to university, such as academia, education, apply, graduated, student, college, etc. The two dots off to the right say Cambridge and Oxford.